AWS for Healthcare & Life Sciences
AWS is the trusted technology and innovation partner to the global healthcare and life sciences industry, providing unmatched reliability, security, and data privacy.
AWS Life Sciences Leaders Symposium for Pharma R&D and Clinical Development Transformation | May 2, 2024
Join us in Boston for an exclusive look at how leading life sciences companies are redefining their business with data and AI to deliver real strategic and financial value.
Explore AWS Health Services
AWS HealthScribe
AWS HealthLake
AWS HealthImaging
Explore AWS for Healthcare & Life Sciences solutions
Healthcare solutions
Life sciences solutions
Genomics solutions
AWS empowers healthcare and life sciences
Philips leverages AWS to unleash the power of AI for clinicians and patients
View Philips' journey with AWS, from using data and analytics to power precision medicine with genomics on AWS, to leveraging AWS to unleash the power of AI for clinicians and patients, to building its HealthSuite Platform on AWS to enable scalability, faster time-to-market, and simplified privacy and security compliance for innovative healthcare and life science solutions.

RUSH creates a population health analytics platform on AWS
Rush University System for Health is reducing the life expectancy gap and addressing the social determinants of health with its Health Equity Care & Analytics Platform built on AWS.

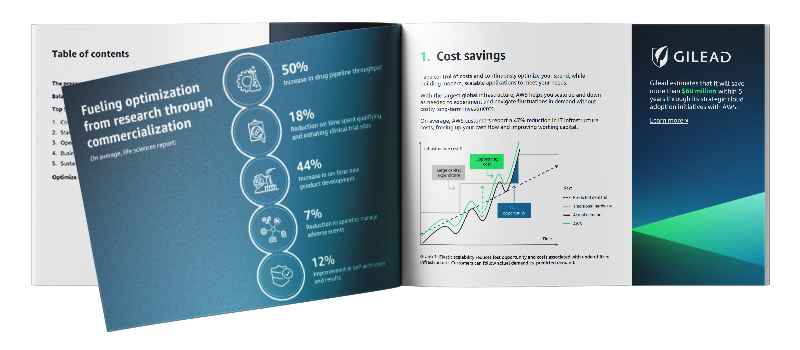
Gilead’s journey from migration to innovation on AWS
Learn how Gilead, leading global biopharmaceutical organization, built a data mesh architecture on AWS to accelerate innovation and drug commercialization.

Realizing the full value of EHR in a digital health environment on AWS with Tufts Medicine
Tufts Medicine implemented its EHR system on AWS, reducing technical debt, improving security, increasing resiliency, reducing costs, and improving caregiver and patient experience.

AstraZeneca uses AWS to do the heavy lifting while it focuses on delivering business value
Watch Amrik Mihal, global IT head for research for AstraZeneca, describe how the company has embraced AI and has used AWS to transform its R&D to deliver medicines to patients much more quickly.






Healthcare and life sciences segments
Healthcare providers
Accelerate innovation, unlock siloed data, and develop personalized care strategies.
Healthcare payors
Manage costs, better understand member populations, and personalize the healthcare experience.
Health tech
Increase your pace of innovation, lower development costs, and speed time to market.
Medical devices
Accelerate product development for secure and scalable medical devices.
Genomics
Translate raw sequencing data into actionable insights and clinical applications.
Innovate with key industry partners
Discover purpose-built health solutions and services from an extensive network of industry-leading AWS Partners who have demonstrated technical expertise and customer success in building healthcare solutions on AWS.
Cerner uses AI/ML and speech recognition to digitize records, improve access to patient records, and help predict health problems.
Change Healthcare Claims Lifecycle AI helps providers and payers optimize the entire claims processing lifecycle.
ConvergeHEALTH MyPath for Clinical enables decentralized clinical trials by providing patients with a mobile app to report data remotely.
DNAnexus created an AIP-based platform using AWS services to share and manage genomics data.
Philips HealthSuite Platform connects devices to the cloud to help unify patient data and make it centrally available.
Illumina leveraged AWS compute services to power its DRAGEN Bio-IT Platform for secondary genomic analysis of sequencing data.

Healthcare solutions available in AWS Marketplace
Accelerate innovation through the continuum of care with third-party healthcare solutions.
Life sciences solutions available in AWS Marketplace
Accelerate life sciences innovation, discovery, and development with third-party purpose built solutions.